
Articolo di Daniel Marella – Full-stack Developer in AzzurroDigitale
Nelle scorse puntate abbiamo capito cosa sono gli LLM e imparato a guidarli con il Prompt Engineering. Sappiamo come parlare con l’AI — ora è il momento di farla uscire dal laboratorio (sandbox) e portarla nel mondo reale. Perché un buon prompt non basta: quando ci sono budget da giustificare, dati sensibili da proteggere e utenti reali che non possono aspettare, le regole del gioco cambiano completamente.
Le due domande che bloccano ogni progetto AI (e le risposte)
Nelle riunioni con i clienti, le domande sono quasi sempre le stesse due. È meglio risponderle subito — perché sono le stesse che bloccano la maggior parte dei progetti AI prima ancora che inizino.
“I miei dati aziendali finiranno su internet?”
La paura è legittima. Ma la risposta, nella maggior parte dei contesti enterprise, è no.
Le principali piattaforme — OpenAI, Anthropic, Azure OpenAI — offrono configurazioni con zero data retention: i dati inviati al modello non vengono usati per addestrare nulla, non vengono conservati sui loro server oltre il tempo strettamente necessario a elaborare la risposta. Non è una promessa commerciale: è scritto nei contratti DPA (Data Processing Agreement), gli stessi che le aziende firmano per GDPR con qualsiasi fornitore cloud.
In pratica, la pipeline sicura si costruisce su tre livelli:
- Anonimizzazione dei dati sensibili prima dell’invio (nomi, CF, numeri di conto — fuori dal prompt)
- Contratto DPA enterprise con il provider scelto
- Audit log di ogni chiamata API, per tracciabilità completa
Con questi tre elementi in posto, il reparto Legal smette di bloccare il progetto.
“Quanto mi costerà a fine mese?”
L’AI non è un abbonamento fisso — si paga esattamente per quello che si usa. È un modello a consumo, come AWS o Google Cloud: se non la usi, non paghi. Se la usi tanto, paghi tanto — ma a quel punto stai anche producendo tanto valore.
Il punto non è quanto costa, ma come si misura il ritorno:
- Risparmio di tempo: un operatore che gestisce 50 ticket al giorno con supporto AI ne gestisce 80-100. La differenza è quantificabile in ore/uomo.
- Riduzione degli errori: un LLM che verifica la coerenza di un documento contrattuale non si stanca, non si distrae, non salta righe.
- Scalabilità immediata: un picco di richieste non richiede assunzioni — l’AI scala in millisecondi.
Per tenere i costi sotto controllo fin dal primo giorno:
- Budget alert configurati sul provider per bloccare la spesa oltre una soglia definita
- Caching delle risposte: nei contesti FAQ o assistenti interni, taglia i costi del 20–40% senza toccare la qualità
- Monitoraggio del consumo per voce (quale feature usa più token? vale il costo?)
L’AI smette di essere un “giocattolo costoso” nel momento in cui la tratti come qualsiasi altro componente software: un owner dedicato, KPI chiari, spesa monitorata. A quel punto non è più una voce di costo — è una leva di margine.
Affitto o proprietà? Come scegliere dove far vivere la tua AI
Come si paga: i token. L’unità di misura dell’AI è il token — circa ¾ di una parola. Funziona come il tassametro di un taxi: scatta sia quando invii il prompt sia quando ricevi la risposta. Un’email generata con 200 parole di istruzione + 300 di output? Circa 670 token. Moltiplicalo per 10.000 richieste al giorno e capisci perché ottimizzare i prompt non è solo una questione di qualità — è economia.
Dove vive l’AI: cloud o in casa? Esistono due filosofie molto diverse:
- Cloud API (OpenAI, Anthropic, Google) — affitti un cervello. Paghi a consumo, non gestisci infrastruttura, hai accesso ai modelli più potenti. Il compromesso: i dati escono dalla tua rete, anche con le garanzie contrattuali.
- Self-hosted (LLaMA, Mistral, Qwen) — compri il cervello e lo tieni in casa. Privacy totale, costi fissi, ma servono GPU e competenze DevOps per mantenerlo attivo. Per dati sanitari, legali o finanziari, spesso è l’unica strada percorribile.
Non esiste la scelta giusta in assoluto — esiste quella giusta per il tuo caso d’uso e il tuo livello di rischio accettabile.
Deep Tech: Approfondimento tecnico e best practices
Quando l’LLM entra in produzione, emergono problemi che in locale non si vedono mai.
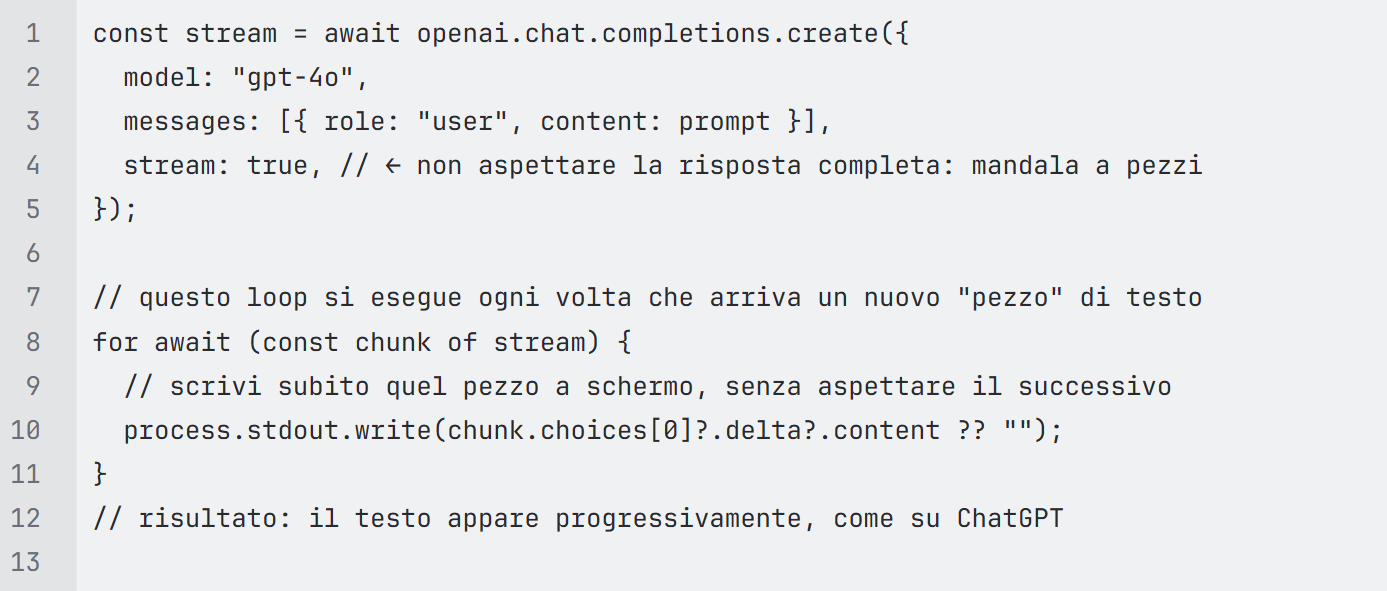
- Streaming delle risposte. I modelli generano testo token per token. Aspettare la risposta completa prima di mostrarla significa lasciare l’utente davanti a uno schermo vuoto per 3–8 secondi. La soluzione è lo streaming via SSE — esattamente come fa ChatGPT: il server invia i chunk man mano che arrivano, la UI li appende in tempo reale. Una decina di righe di codice che trasformano completamente la percezione di velocità dell’app.
- Rate limit e retry logic. Le API hanno limiti di richieste al minuto. Sotto carico si raggiungono facilmente. Servono retry con backoff esponenziale e, nei sistemi critici, una coda di messaggi (Redis + BullMQ, oppure SQS) per assorbire i picchi senza errori a cascata verso l’utente.
- Caching. Domande identiche o semanticamente simili possono restituire la stessa risposta. Cachare per hash del prompt — o usando il semantic caching di LangChain — riduce il consumo di token in modo misurabile. In certi prodotti il risparmio supera il 35% già dal primo mese.
- Guardrails. Nessun sistema AI in produzione dovrebbe girare senza protezioni. Filtri sull’input per bloccare prompt injection e richieste fuori perimetro; filtri sull’output per rilevare allucinazioni o contenuti inappropriati prima che raggiungano l’utente. Non è paranoia — è ingegneria del software di base.
Portare un LLM in produzione non è un lavoro da smanettoni che sanno scrivere prompt: è architettura software, gestione degli errori, sicurezza e visione economica. Quando fatto bene, l’AI smette di essere un esperimento e diventa un componente affidabile del prodotto.
Conclusione e prossima puntata
Prossima puntata — Agenti Autonomi. Cosa succede quando l’AI smette di scrivere testi e inizia a fare cose: chiamare API, inviare email, interrogare database, prendere decisioni in autonomia. Un cambio di paradigma che sta già ridefinendo come le aziende operano. Restate sintonizzati.