
Articolo di Mattia Gottardello – Full-stack Developer in AzzurroDigitale
Large Language Model e sistemi RAG stanno trasformando il modo in cui le aziende utilizzano l’intelligenza artificiale. Queste tecnologie permettono di automatizzare il supporto clienti con risposte precise, gestire documenti aziendali in modo intelligente e interrogare database in linguaggio naturale. L’articolo esplora il funzionamento di questi strumenti, i vantaggi concreti per il business e i limiti tecnici da tenere presenti: una guida strategica per integrare l’AI generativa nella tua azienda.
Perché LLM e RAG sono una svolta per le aziende
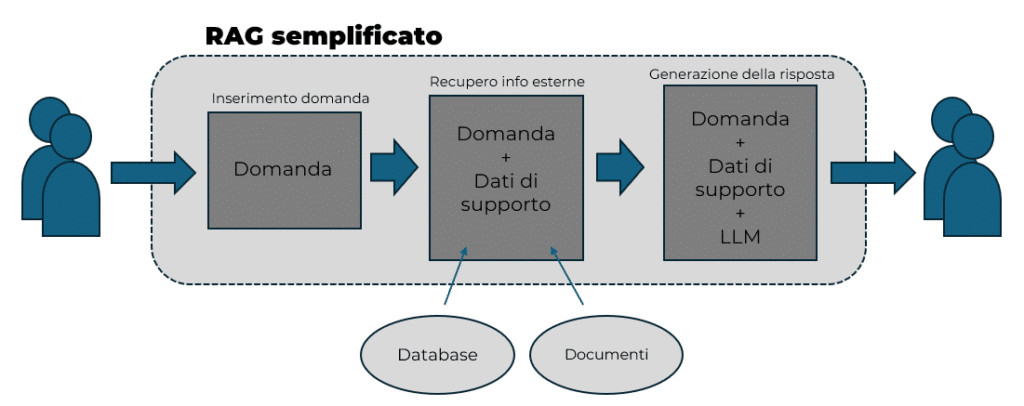
Le tecnologie LLM (Large Language Model) e RAG (Retrieval-Augmented Generation) stanno rivoluzionando il modo in cui le aziende possono gestire, valorizzare e mettere a disposizione la propria conoscenza. In un contesto in cui la quantità di dati e documenti cresce ogni giorno, trovare rapidamente l’informazione giusta diventa una sfida sempre più complessa. Qui entrano in gioco gli LLM e, soprattutto, i sistemi RAG.
Immagina un’azienda che deve fornire supporto tecnico ai clienti: grazie a un sistema RAG, il chatbot può consultare in tempo reale manuali, FAQ, documentazione interna e rispondere in modo preciso anche a domande molto specifiche, riducendo drasticamente i tempi di attesa e migliorando la soddisfazione del cliente. Oppure pensa a un team di consulenti che, invece di cercare tra decine di file e normative, può ottenere risposte puntuali e aggiornate semplicemente formulando una domanda in linguaggio naturale.
Queste tecnologie permettono anche di:
- Automatizzare processi ripetitivi come la compilazione di report, la ricerca di dati o la generazione di documenti
- Ridurre il rischio di errori grazie a risposte basate su fonti verificate e aggiornate
- Personalizzare l’esperienza utente attingendo sia a dati pubblici che a informazioni aziendali riservate
- Integrare dati strutturati e non strutturati: i RAG possono combinare informazioni provenienti da database, documenti, offrendo una visione completa e trasversale
e tutto questo senza dover riaddestrare il modello ogni volta che cambiano i dati.
Naturalmente, adottare queste soluzioni richiede attenzione: bisogna valutare i limiti tecnici (come la gestione dei token, dei chunk e dei vettori), i costi di infrastruttura e la qualità delle fonti utilizzate. Tuttavia, i benefici in termini di efficienza, rapidità di accesso all’informazione e qualità del servizio sono tali da rendere LLM e RAG una scelta strategica per tutte le aziende che vogliono innovare e restare competitive.
In questo articolo scoprirai come funzionano queste tecnologie, quali sono i loro limiti, i casi d’uso più diffusi e le sfide da affrontare per adottarle con successo nel tuo business.
Cos’è un LLM?
Un Large Language Model è “un’intelligenza artificiale” addestrata su enormi quantità di testo per comprendere e generare linguaggio naturale. Questi modelli, come GPT-4, sono in grado di rispondere a domande, scrivere testi, tradurre lingue e molto altro.
Esempi di utilizzo quotidiano:
- Chatbot intelligenti (es. assistenti virtuali)
- Generazione automatica di email o documenti
- Traduzione automatica
Per addestrare e far funzionare questi modelli servono enormi risorse computazionali, come potenti GPU (Graphics Processing Unit, ovvero scheda grafica) e server specializzati. Anche l’uso quotidiano (inference1) può richiedere molta potenza di calcolo, motivo per cui spesso vengono eseguiti su cloud.
Limiti degli LLM: aggiornamento e bias culturali
Uno dei principali limiti degli LLM è che la loro conoscenza si ferma alla data in cui sono stati addestrati. Questo significa che tutto ciò che il modello “sa” deriva dai dati raccolti fino a quel momento: eventi, scoperte scientifiche, cambiamenti sociali o tecnologici successi dopo la fine dell’addestramento non sono presenti nella sua “memoria”. Ad esempio, un LLM addestrato nel 2023 non conoscerà fatti avvenuti nel 2024 o nel 2025.
Inoltre, gli LLM riflettono la cultura, i valori e i pregiudizi presenti nei dati su cui sono stati addestrati. Se i testi di partenza sono prevalentemente in una lingua, di una certa area geografica o rappresentano un certo modo di pensare, il modello tenderà a riprodurre quelle stesse prospettive. Questo può portare a risposte che non sono neutrali o che non tengono conto della diversità culturale e sociale.
Per questi motivi, è importante usare gli LLM con spirito critico, essere consapevoli dei loro limiti e, quando serve, integrarli con tecnologie come i RAG che permettono di accedere a informazioni aggiornate e più specifiche.
Cosa sono i RAG?
La Retrieval-Augmented Generation è una tecnica che combina la potenza degli LLM con la capacità di recuperare informazioni aggiornate da fonti esterne (database, documenti, web). In pratica, il modello non si basa solo su ciò che ha imparato durante l’addestramento, ma può “andare a cercare” informazioni fresche e pertinenti.
In questo modo:
- Le risposte possono essere sempre aggiornate e basate su dati reali
- Si riduce il rischio di risposte inventate perché il modello si basa su fonti concrete
- È possibile personalizzare le risposte usando dati aziendali o privati
- Si amplia l’utilità degli LLM, rendendoli strumenti più flessibili e adatti a contesti professionali e dinamici.
Come funziona nella pratica?
Quando fai una domanda a un sistema RAG, questo:
- Cerca nei suoi archivi o su internet i documenti più rilevanti per la tua richiesta
- Passa queste informazioni al modello linguistico
- Genera una risposta più precisa e aggiornata.
Esempi di utilizzo dei RAG:
- Motori di ricerca avanzati (es. Perplexity, Bing Chat): rispondono citando fonti aggiornate
- Assistenza clienti: chatbot che rispondono su prodotti e servizi usando documentazione interna
- Strumenti aziendali: ricerca intelligente su documenti, policy, manuali
La qualità delle risposte dipende direttamente dalla qualità e dalla pertinenza delle fonti a cui il modello ha accesso: più i documenti recuperati sono affidabili e coerenti con la richiesta, più l’output sarà accurato. Per questo motivo è fondamentale integrare il sistema con le fonti giuste, che possono essere database aziendali, knowledge base interne o contenuti provenienti dal web.
Quando parliamo di sistemi che “leggono” e “capiscono” grandi quantità di testo, dobbiamo però ricordare che le macchine non interpretano le parole come facciamo noi. Per elaborare il linguaggio, i computer devono trasformare il testo in una forma comprensibile e manipolabile per loro. Qui entrano in gioco concetti come token, chunk, vettori e similarity search: strumenti che consentono ai RAG di suddividere, rappresentare e confrontare il testo in maniera efficiente, così da individuare le informazioni più rilevanti e generare risposte pertinenti.
Perché si parla di token, chunk, vettori e similarity search
I RAG sono sistemi che combinano la capacità di generare testo (come fanno i grandi modelli linguistici) con la possibilità di recuperare informazioni da una raccolta di documenti o dati. Questo permette di ottenere risposte più aggiornate, precise e personalizzate.
Come funziona un RAG in pratica?
- Ricezione della domanda: L’utente scrive una domanda o una richiesta
- Recupero delle informazioni: Il sistema cerca nei suoi archivi (database, documenti, web) i testi più rilevanti per rispondere
- Generazione della risposta: Il modello linguistico usa le informazioni recuperate per costruire una risposta chiara e completa
Per fare tutto questo, i RAG devono “capire” e confrontare grandi quantità di testo.
Qui entrano in gioco i termini tecnici:
Token
Gli LLM non leggono il testo come una persona, ma lo dividono in token, cioè piccole unità (parole, parti di parola, punteggiatura). Questo serve per gestire il testo in modo più efficiente e uniforme. Ogni modello ha un limite massimo di token che può gestire in una sola volta: se la domanda o i documenti sono troppo lunghi, bisogna tagliarli. Sono inoltre l’unità fondamentale su cui alcuni provider di servizi AI basano i sistemi di fatturazione sui modelli a pagamento.
Chunk
Per rispettare il limite dei token, i testi lunghi vengono suddivisi in chunk: piccoli pezzi di testo, ognuno dei quali può essere elaborato dal modello. Questo processo è fondamentale per permettere al sistema di “digerire” anche documenti molto estesi, ma può comportare la perdita di parte del contesto se le informazioni importanti sono distribuite su più chunk.
Vettori
Ogni chunk di testo viene trasformato in un vettore, cioè una sequenza di numeri che rappresenta il significato di quel pezzo di testo. Questa trasformazione permette al sistema di confrontare testi diversi in modo matematico, anche se usano parole diverse per esprimere concetti simili.
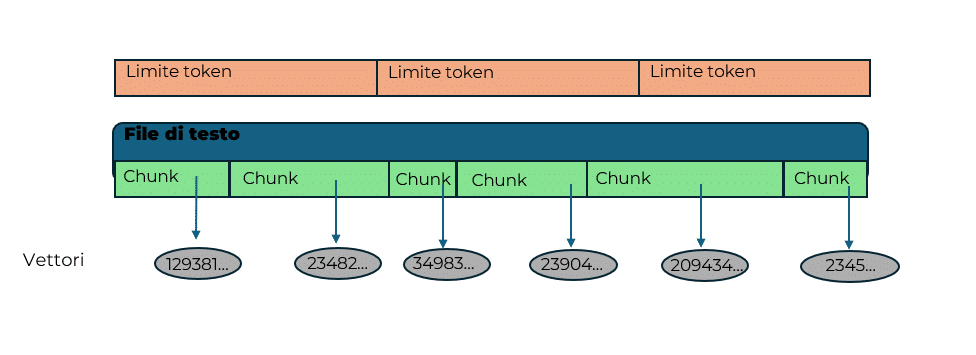
Similarity search
Una volta che tutti i chunk sono stati trasformati in vettori, il sistema può usare la similarity search (ricerca per similarità) per trovare, tra tutti i pezzi di testo disponibili, quelli più simili alla domanda dell’utente. In pratica, il sistema cerca i vettori che “assomigliano” di più a quello della domanda, cioè che rappresentano argomenti o concetti simili.
Perché tutto questo è importante?
- Efficienza: Suddividere il testo in chunk e lavorare con vettori permette di gestire grandi quantità di dati in modo rapido
- Precisione: La similarity search aiuta a trovare le informazioni più pertinenti, anche se espresse in modi diversi
- Limiti tecnici: I limiti sui token e sulle dimensioni dei vettori dipendono dal modello usato e influenzano la quantità di testo che si può analizzare e la qualità delle risposte.
Flussi di funzionamento
L’obiettivo di questi paragrafi è:
- Inserimento dati di supporto: far comprendere come i dati vengano trasformati passo dopo passo: dai FILE originali, che vengono suddivisi in CHUNK più piccoli, fino alla rappresentazione numerica tramite VETTORI, pronta per essere utilizzata dal sistema
- Domanda/risposta: far comprendere come il sistema, a partire da una domanda, individua i file di supporto pertinenti e genera una risposta, fornendo informazioni il più possibile accurate e basate sui dati effettivamente recuperati in relazione alla domanda posta.
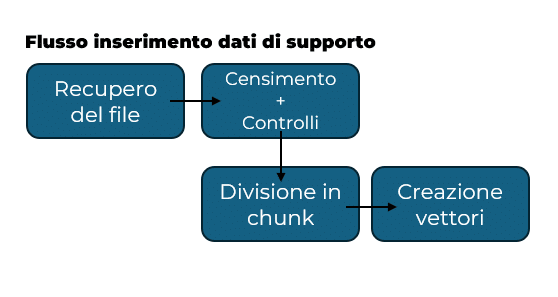
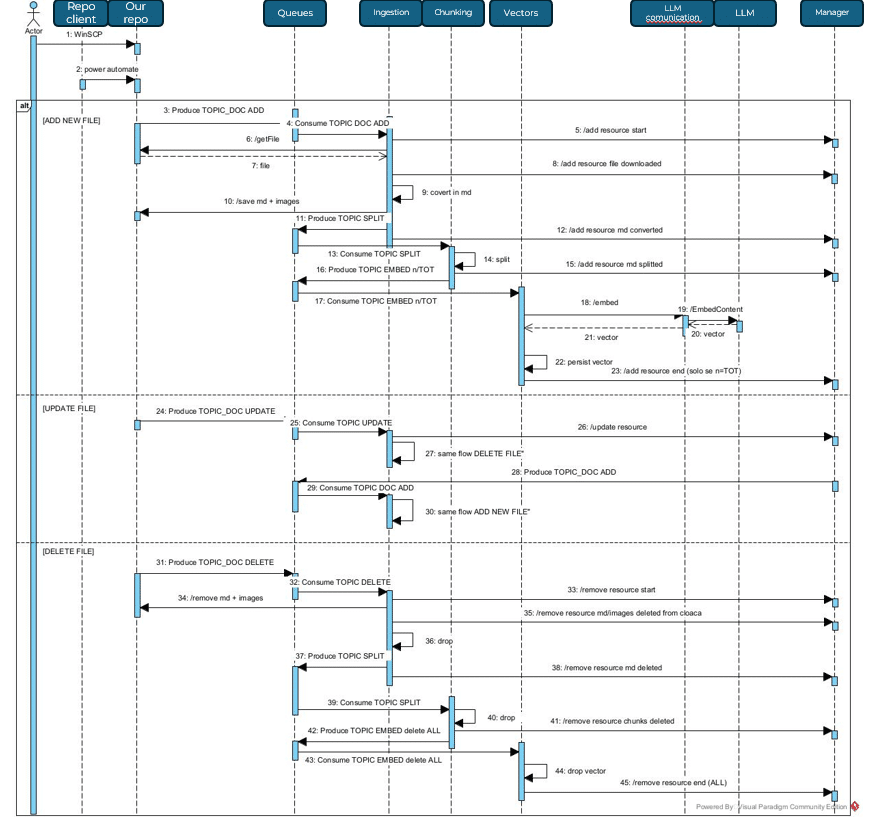
Flusso di inserimento dei dati di supporto
Si parte da recupero dei file che il cliente può mettere in autonomia in una “cartella” remota, una volta che il sistema rileva l’arrivo di un nuovo file una parte di esso si occupa di recuperarlo. Il nuovo documento viene censito e ci si occupa di effettuare eventuali controlli su dimensioni e formato del file. Questo perchè è necessario sapere come e con cosa si sta lavorando.
Una volta che ci siamo assicurati che il file rispetti i nostri vincoli possiamo partire con la sua divisione in chunk secondo la metodologia da noi scelta. Ultimo step riguarda la conversione in vettore.
Alla fine del flusso sarà quindi possibile sapere, partendo da un vettore, a che chunk apparteneva e a sua volta da che file è stato generato quel chunk.
Flusso domanda/risposta:
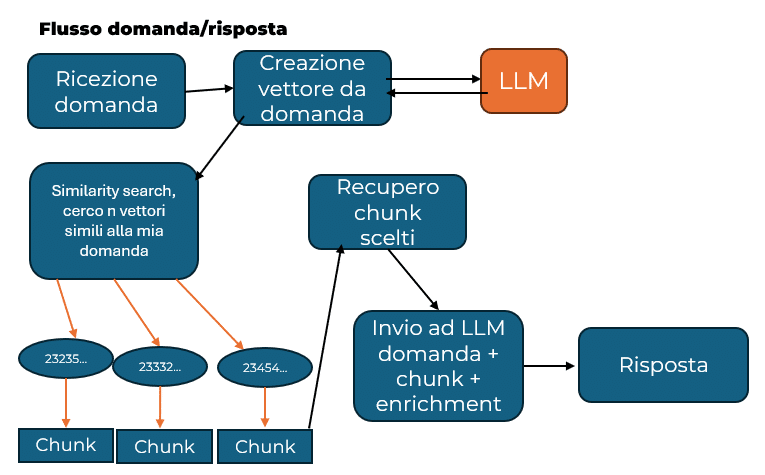
Arriva ora il momento in cui l’utente effettua la domanda: essa viene convertita in vettore e poi viene effettuata la similarity search con i vettori presenti nel nostro sistema. Ovviamente tutti i vettori daranno un risultato questo perché si sta misurando una “distanza“ tra due “idee“, e questa distanza darà sempre un valore. Bisogna quindi decidere una soglia minima che farà rientrare i vettori in quelli candidati per concorrere alla generazione della risposta. Il vincolo può essere imposto sia dal punto di vista del minimo valore per rientrare nell’insieme ma anche dal numero di vettori massimi che possono entrarci.
Una volta individuati quindi i vettori che concorrono alla generazione della risposta il gioco diventa semplice, dato che ogni vettore è collegato al chunk che lo ha generato si andrà a recuperare tutti i chunk scelti e mandati assieme alla domanda all’LLM chiedendo di generare una risposta basata sulla domanda e sulle informazioni che noi abbiamo fornito.
È possibile (se non consigliabile), dare anche dei file aggiuntivi in pasto al sistema di generazione della risposta che impostano o cercano di impostare delle linee guida per la risposta da parte dell’LLM.
Questi file li abbiamo nominati come file di arricchimento (enrichment files).
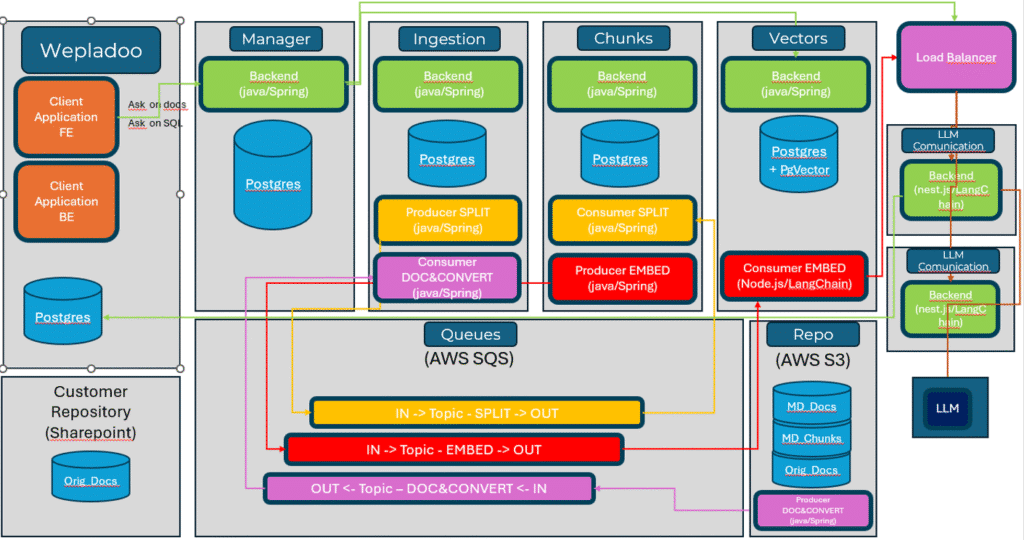
Wepladoo per Fratelli Poli
Nel business case affrontato dal nostro team (se vuoi approfondire lo trovi qui), il cliente ci ha chiesto di sviluppare un chatbot capace di rispondere a domande specifiche sfruttando due fonti principali di informazioni: i documenti aziendali che il cliente mette a disposizione attraverso una cartella remota e i dati presenti direttamente nel database applicativo di Wepladoo. L’obiettivo era permettere agli utenti di ottenere risposte precise e contestualizzate senza dover consultare manualmente né i documenti né il database.
Quale migliore utilizzo per un RAG?
Abbiamo quindi implementato un’applicativo web che esegue le operazioni sopra descritte, con le quali abbiamo raggiunto questo obbiettivo.
La suddivisione delle operazioni ci ha permesso di dividere le responsabilità e i carichi di elaborazione rendendo però la sfida più complessa dal punto di vista dell’orchestrazione dei flussi.
Abbiamo quindi analizzato i vari LLM, decidendo di appoggiarci a Gemini per un semplice motivo: maggiore flessibilità per quanto riguarda dimensioni e limiti del testo che riesce a gestire, sia dal punto di vista delle domande sia per la quantità di informazioni che è possibile utilizzare per ottenere risposte con dati di supporto.
Abbiamo anche messo in piedi un meccanismo che permette il recupero automatico dei file, in questo modo il sistema risulta sempre aggiornato in base a quello che il cliente carica in una nostra “cartella” remota.
Un ruolo importate lo ha svolto la figura del prompt engineer. Dato che dovevamo fornire dei limiti e delle linee guida per la generazione della risposta, abbiamo sviluppato dei prompt (in poche parole: delle frasi, un piccolo testo) che vengono sempre annessi alle domande e la buona scrittura di questi file è abbastanza proporzionale alla generazione di buone risposte.
Una sfida aggiuntiva anche è legata al fatto che il cliente richiedeva di poter ottenere informazioni sull’applicativo Wepladoo direttamente da chatbot. Quindi abbiamo pensato ad un meccanismo che lavora in modo molto simile ad un normale RAG ma che si occupa anche nel recuperare i dati (direttamente dal database) aggiornati al momento della domanda per fornire una risposta all’utente.
Il sistema, integrato con Wepladoo, ha consentito agli operatori di accedere in tempo reale a informazioni provenienti sia da diversi documenti aziendali sia dai dati presenti nel database, semplificando notevolmente la ricerca e l’ottenimento delle risposte.
Deep Tech per gli addetti ai lavori
Come funziona un RAG
Un sistema RAG tipico si compone di due parti principali:
- Retriever: Dato un input (es. una domanda), cerca i documenti più rilevanti in un database o in un indice vettoriale (spesso usando tecniche di embedding come FAISS, Pinecone, o Elasticsearch)
- Generator: L’LLM prende i documenti recuperati e li usa come contesto per generare una risposta precisa e informata.
Divisione dei compiti
Lo sviluppo di un RAG è possibile effettuarlo con un infrastruttura monolitica oppure a micro-servizi, e ovviamente questo si basa sulle necessità. Le parti in gioco viste come metodi o singoli micro-servizi riguardano:
- Ingestion dei file: recuperare e gestire le fonti di dati aggiornate che poi saranno utilizzate come base per generare le risposte
- Chunking dei file: divisione dei file recuperati per fare in modo che rientrino nei limiti sopra descritti dei vari LLM
- Conversione in vettore: conversione in vettori dei pezzi di file generati e catalogazione degli stessi in base al file di appartenenza
- Manage del flusso domanda-risposta: una volta preparati vettori, chunk e file è necessario mettere in pratica il vero funzionamento del RAG ovvero l’implementazione del sistema di retriving e l’utilizzo del sistema di generation.
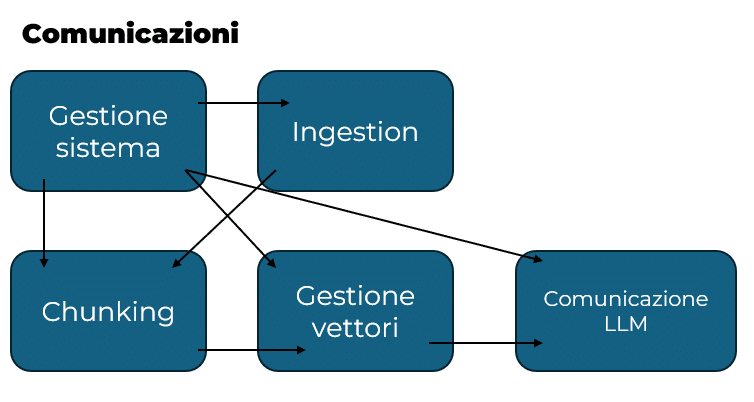
Ingestion
In questo processo si deve prevedere il recupero da remoto o da una posizione fissa di uno o più file, la loro prima catalogazione all’interno del sistema e la gestione dei vari formati supportati.
La decisione dei formati supportati andrà a gravare sul processo di chunking il quale è il primo punto in cui effettivamente si andrà ad accedere al contenuto dei file. Il sistema deve saper riconoscere quali formati sono ammessi e quali no, questo appunto per evitare di far entrare nel sistema dei file non supportati che andrebbero a rendere inutilizzabile l’intera applicazione.
Il censimento dei file è molto utile per fornire anche funzionalità legate all’aggiornamento dei file caricati in momenti diversi, rimozione di file obsoleti che quindi non concorrono o non possono più concorrere alla generazione di risposte e/o molto semplicemente per controllare su che dati si basano le risposte generate (citazione delle fonti).
Tutta la parte di ingestion utilizza anche un sistema di code, che permette quindi di mantenere ordinata le ricezione dei vari aggiornamenti nella cartella remota, di non congestionare il sistema in casi di inserimenti massivi e di migliorare quello che è tutto il flusso a partire dal censimento fino ad arrivare alla vettorializzazione.
In seguito vediamo come è il flusso delle chiamate per ottenere una corretta implementazione del sistema.
Chunking
Il chunking dei file avviene come secondo passo verso l’elaborazione completa delle nuove informazioni. Sapendo i limiti del modello linguistico su cui ci si basa e essendo consapevoli delle differenza fra un metodo di chunking ed un altro, bisogna scegliere come procedere per dividere i file che sono stati portati dentro al sistema.
Quindi in poche parole capire dopo quanto testo creare un chunk.
Ci sono diversi metodi di chunking ognuno dei quali comporta pro e contro:
- Chunking basato su numero di token: il testo viene suddiviso in blocchi che contengono un numero fisso di token (ad esempio, 256 o 512 token per chunk)
- Chunking basato su paragrafi o frasi: il testo viene suddiviso rispettando i confini naturali di frasi o paragrafi
- Chunking con sovrapposizione (overlapping): ogni nuovo chunk condivide una parte del testo con il chunk precedente (ad esempio, 50 token di sovrapposizione)
- Chunking semantico: il testo viene suddiviso in base al significato, identificando automaticamente i punti in cui cambia argomento o si conclude un concetto
- Chunking personalizzato: il chunking viene adattato alle esigenze specifiche dell’applicazione (es. sezioni di manuali, capitoli di libri, voci di database).
Conversione in vettore
Una volta generati i chunk che rispettano i vincoli imposti dall’LLM in uso, è possibile passare alla generazione dei vettori.
I vettori poi saranno salvati e collegati sia al chunk da cui sono stati generati sia al file a cui appartiene quel chunk, questo permetterà di ottenere le fonti da cui è nata una determinata risposta.
La conversione in vettore serve principalmente per poter effettuare la similarity search, la quale permette di estrarre i chunk più simili alla domanda effettuata dall’utente che quindi aumenta notevolmente la possibilità di ottenere una risposta congrua alla domanda posta al sistema.
Per ottenere una similarity search è necessario quindi convertire anche la domanda in un vettore e per questo anche nelle domande sarà presente un limite di caratteri.
Tecniche di similarity search
La similarity search è il processo che permette ai sistemi RAG di trovare, tra tanti pezzi di testo (chunk), quelli più simili alla domanda dell’utente. Esistono diverse tecniche per confrontare i vettori che rappresentano i testi, ognuna con vantaggi e limiti:
- Distanza Coseno (Cosine Similarity)
- Distanza Euclidea
- Distanza di Manhattan (o L1)
- Approximate Nearest Neighbor (ANN)
Esistono anche metodi più sofisticati, come la similarità basata su reti neurali o l’uso di hashing per ridurre la complessità dei calcoli. Queste tecniche vengono scelte in base alle esigenze di precisione, velocità e risorse disponibili.
Comunicazioni verso LLM
Per interagire con i modelli LLM è possibile utilizzare librerie che, attraverso metodi dedicati, mettono a disposizione in un unico punto le API di diversi provider AI.
Un esempio significativo è LangChain, che offre supporto sia per JavaScript che per Python. Poiché gran parte di queste tecnologie nasce in ambiente Python, l’implementazione in questo linguaggio risulta più completa e matura rispetto a quella in JavaScript, che comunque garantisce tutte le funzionalità essenziali.
Grazie a questi strumenti sono state sviluppate funzioni che consentono, in modo semplice, di generare vettori e inviare domande ai vari LLM, utilizzando soltanto le chiavi di accesso e specificando il modello desiderato.
Domanda/Risposta
Ecco una piccola rappresentazione del flusso di chiamate per quanto riguarda la generazione della risposta a partire dalla domanda.
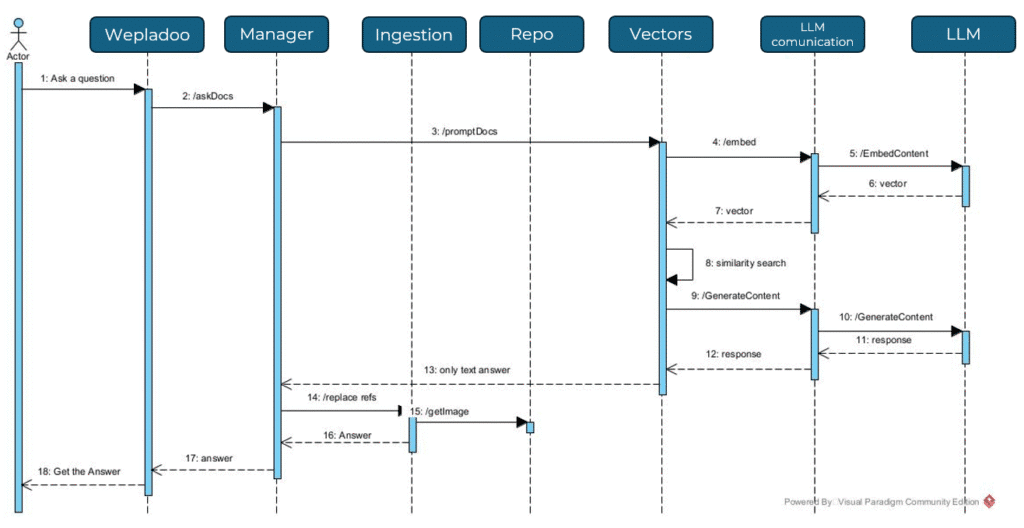
RAG DB connected
L’implementazione di questa piccola variante da un normalissimo RAG, unisce uno step aggiuntivo che è quello di recupero delle informazioni direttamente da un database remoto.
Requisito fondamentale è quello che si sappia la struttura del database, grazie alla quale sarà possibile chiedere la generazione di una query 2per il recupero dei dati da utilizzare per la generazione della risposta.
Il flusso di preparazione è quindi:
- creare un file che contenga (in linguaggio SQL3) le istruzioni con cui è creato il database di interesse
- far elaborare il file al sistema trattandolo come un normalissimo file documento
- utilizzare il file senza sfruttare la similarity search (si sa che la struttura è statica quindi contenuta solo in quel file che a sua volta genera o può generare un chunk)
Il flusso di domanda-risposta:
- Ottenere la domanda
- Recuperare il file che contiene la struttura del database
- Chiedere al’LLM scelto di generare una query che sfrutta la combinazione domanda e struttura del database
- Controlli vari di validazione/blocco di operazioni pericolose e esecuzione della query sul database
- Ottenimento dei risultati (i quali non è detto che siano presenti)
- Generazione della risposta che vede coinvolta ancora una volta la domanda assieme ai risultati ottenuti, questa volta la risposta sarà fornita in linguaggio naturale
Per facilitare la gestione dei due meccanismi è stato deciso di tenere separate anche graficamente i due chatbot uno che quindi permette di fare domande e ottenere risposte basandosi sui documenti e uno basandosi sui dati a database.
Glossario del developer
- L’inference è la fase in cui un modello di intelligenza artificiale viene utilizzato per generare risposte o fare previsioni dopo essere stato addestrato. In pratica, quando scrivi una domanda o un testo, il modello elabora l’input e produce un output (ad esempio, una risposta o un completamento di frase). A differenza dell’addestramento, che richiede molta potenza di calcolo e tempo, l’inference è il momento in cui il modello “mette in pratica” ciò che ha imparato, tipicamente in tempo reale o quasi, per fornire risposte agli utenti.
↩︎ - Una query è una richiesta formulata a un database o a un sistema informatico per ottenere informazioni specifiche, solitamente tramite un linguaggio strutturato come SQL.
↩︎ - Structured Query Language, linguaggio che permette l’interrogazione e di effettuare operazioni in un database.
↩︎