
Article by Daniel Marella – Full-Stack Developer at AzzurroDigitale
In the previous articles, we explored what LLMs are and learned how to guide them through Prompt Engineering. We now know how to communicate effectively with AI — but it’s time to take it out of the sandbox and into the real world.
Because a well-crafted prompt is not enough: when there are budgets to justify, sensitive data to protect, and real users who can’t afford to wait, the rules of the game change completely.
The Two Questions That Stall Every AI Project (and the Answers)
In meetings with clients, the same two questions almost always come up. It’s best to address them right away—because they’re the very questions that prevent most AI projects from getting off the ground in the first place.
“Will my company’s data end up on the internet?”
The concern is legitimate. But in most enterprise environments, the answer is no.
Major platforms—including OpenAI, Anthropic, and Azure OpenAI—offer configurations with zero data retention: data sent to the model is not used for training purposes and is not stored on their servers beyond the time strictly necessary to process the response. This is not a marketing promise; it is explicitly stated in Data Processing Agreements (DPAs), the same contractual framework companies rely on for GDPR compliance with any cloud service provider.
In practice, a secure AI pipeline is built on three layers:
- Anonymization of sensitive data before submission (names, tax IDs, bank account numbers—kept out of the prompt).
- Enterprise DPA agreement with the selected provider.
- Comprehensive audit logging of every API call, ensuring full traceability.
With these three elements in place, the Legal department stops being a roadblock to the project.
“How much will it cost me at the end of the month?”
AI is not a fixed subscription cost—it’s billed exactly according to usage. It follows a consumption-based model, much like AWS or Google Cloud: if you don’t use it, you don’t pay. If you use it heavily, costs increase accordingly—but by that point, you’re also generating significant value.
The key question isn’t how much it costs, but how its return on investment is measured:
- Time savings: an operator who handles 50 tickets per day can manage 80–100 with AI support. The difference can be directly quantified in labor hours.
- Error reduction: an LLM that reviews the consistency of a contractual document doesn’t get tired, lose focus, or skip lines.
- Immediate scalability: a spike in demand doesn’t require hiring—AI scales in milliseconds.
To keep costs under control from day one:
- Budget alerts configured with the provider to stop spending beyond a defined threshold.
- Response caching: in FAQ contexts or internal assistants, it reduces costs by 20–40% without impacting quality.
- Consumption monitoring by feature: which capability consumes the most tokens, and is it worth the cost?
AI stops being an “expensive toy” the moment you treat it like any other software component: a dedicated owner, clear KPIs, and monitored spending. At that point, it’s no longer a cost line—it becomes a margin lever.
Rent or ownership? How to decide where your AI should live
How it’s paid: tokens. The unit of measurement for AI is the token—roughly ¾ of a word. It works like a taxi meter: it starts running both when you send the prompt and when the model returns the response. An email generated with 200 words of instructions + 300 words of output? About 670 tokens. Multiply that by 10,000 requests per day and it becomes clear why prompt optimization is not just a matter of quality—it’s economics.
Where does AI live: cloud or on-premise? There are two very different philosophies:
- Cloud APIs (OpenAI, Anthropic, Google) — you rent a brain. You pay per use, you don’t manage infrastructure, and you get access to the most powerful models. The trade-off: data leaves your network, even with contractual guarantees in place.
- Self-hosted (LLaMA, Mistral, Qwen) — you own the brain and keep it in-house. Full privacy, fixed costs, but you need GPUs and DevOps expertise to keep it running. For healthcare, legal, or financial data, it’s often the only viable path.
There is no universally “right” choice—only the right one for your specific use case and your acceptable level of risk.
Deep Tech: Technical Insights and Best Practices
When an LLM goes into production, issues emerge that you never see in a local environment.
- Response streaming. Models generate text token by token. Waiting for the full response before displaying it means leaving the user staring at a blank screen for 3–8 seconds. The solution is streaming via SSE—exactly what ChatGPT does: the server sends chunks as they are produced, and the UI appends them in real time. About ten lines of code that completely transform the perceived speed of the application.
- Rate limits and retry logic. APIs have requests-per-minute limits. Under load, these limits are easily reached. You need retry logic with exponential backoff and, in critical systems, a message queue (Redis + BullMQ, or SQS) to absorb traffic spikes without cascading errors reaching the user.
- Caching. Identical or semantically similar questions can return the same response. Caching by prompt hash—or using semantic caching via LangChain—reduces token consumption in a measurable way. In some products, savings exceed 35% within the first month.
- Guardrails. No production AI system should run without safeguards. Input filters to block prompt injection and out-of-scope requests; output filters to detect hallucinations or inappropriate content before it reaches the user. This isn’t paranoia—it’s basic software engineering.
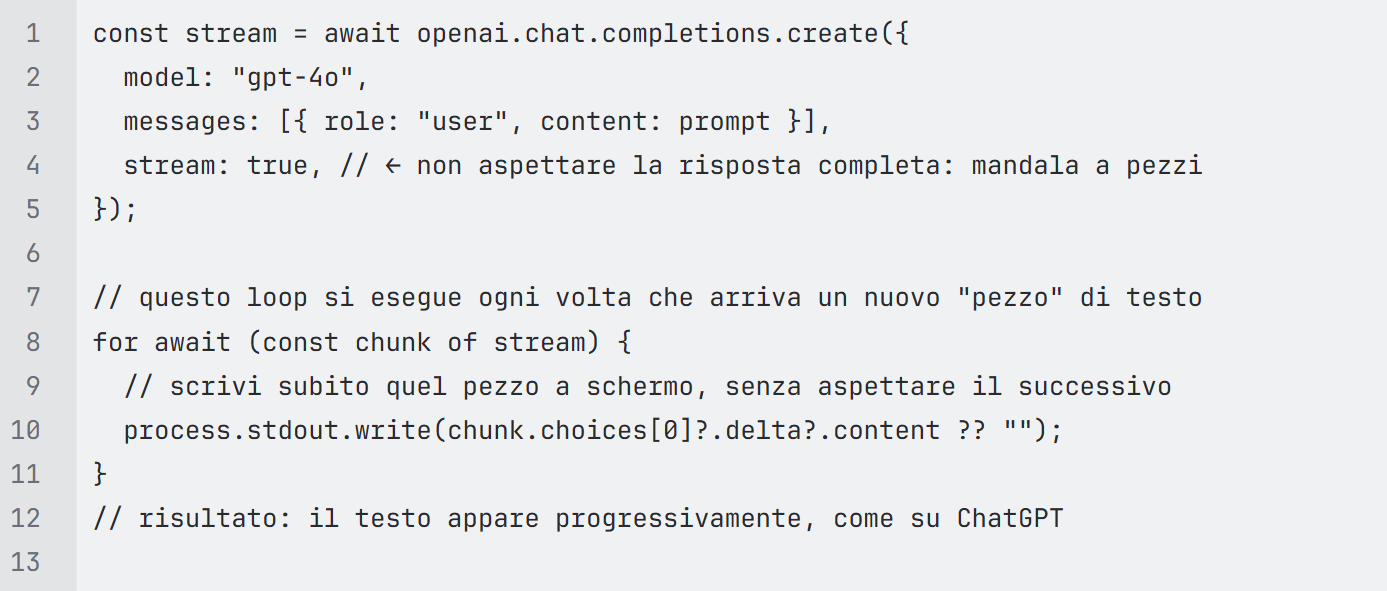
Bringing an LLM into production is not a job for tinkerers who know how to write prompts: it’s software architecture, error handling, security, and economic thinking. When done properly, AI stops being an experiment and becomes a reliable component of the product.
Conclusion and Next Episode
Next episode — Autonomous Agents. What happens when AI stops generating text and starts doing things: calling APIs, sending emails, querying databases, and making decisions autonomously. A paradigm shift that is already redefining how companies operate. Stay tuned.