
Articolo di Nicola Boscaro – Full-stack Developer in AzzurroDigitale
Il primo episodio di “LLM nel Mondo Reale” è pensato per imprenditori, manager e team tech che vogliono capire se gli LLM sono davvero un’opportunità concreta per la propria azienda. L’obiettivo è andare oltre l’hype e spiegare, in modo chiaro e pratico, come usarli per generare valore reale. Tra casi d’uso, scelte architetturali e confronto tra Cloud e Open Source, l’articolo condivide esperienze e lezioni imparate direttamente sul campo dal team di sviluppo, con un focus su risultati, costi e messa in produzione.
Benvenuti alla prima puntata di “LLM nel Mondo Reale”, la miniserie in cui il nostro team di sviluppo smette di parlare di teoria e vi racconta cosa significa davvero portare l’intelligenza artificiale generativa in produzione. Nessun hype, nessuna magia: solo casi concreti, architetture reali e lezioni imparate sulla propria pelle. Allacciate le cinture.
Business Case: capire il valore per l’azienda
Partiamo da una domanda diretta: perché la vostra azienda dovrebbe investire negli LLM oggi, e non tra due anni?
La risposta è semplice: i vostri competitor probabilmente lo stanno già facendo.
Gli LLM non sono “chatbot sofisticati”. Sono motori capaci di comprendere, analizzare e produrre testo a una velocità inarrivabile. Questo significa poter prendere processi aziendali lenti e macchinosi, che oggi rubano ore di lavoro manuale, e risolverli in una manciata di secondi. Pensate a:
- Supporto clienti che risponde in modo coerente e personalizzato, 24/7, senza un call center.
- Analisi di documenti (contratti, email, report) che vengono classificati e riassunti automaticamente.
- Interfacce conversazionali che permettono ai vostri dipendenti di interrogare dati aziendali complessi in linguaggio naturale, senza conoscere SQL.
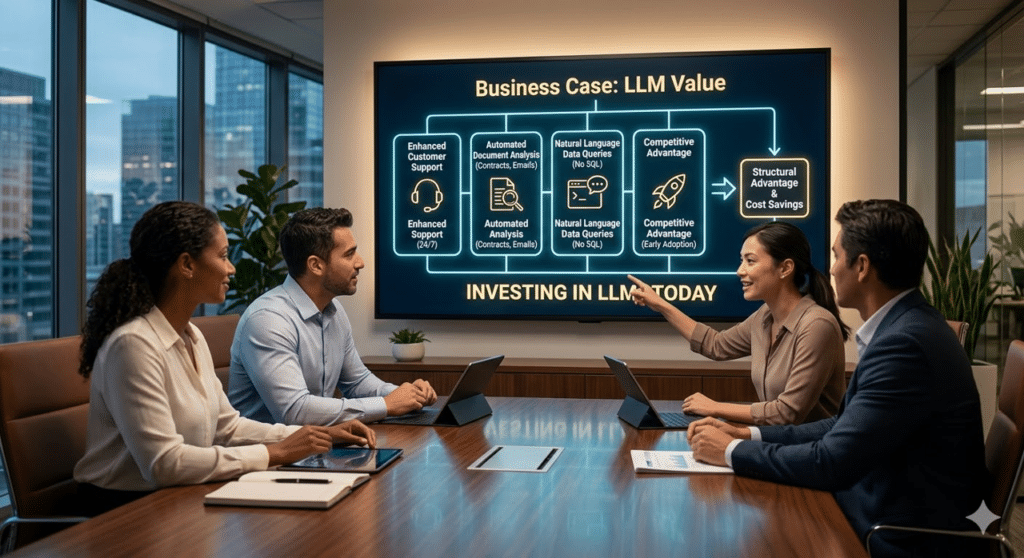
Il vantaggio competitivo non sta nell’adottare l’AI: sta nel farlo prima che diventi lo standard. Chi costruisce oggi le proprie pipeline intelligenti avrà un vantaggio strutturale difficile da colmare.
How it works: semplificare la complessità
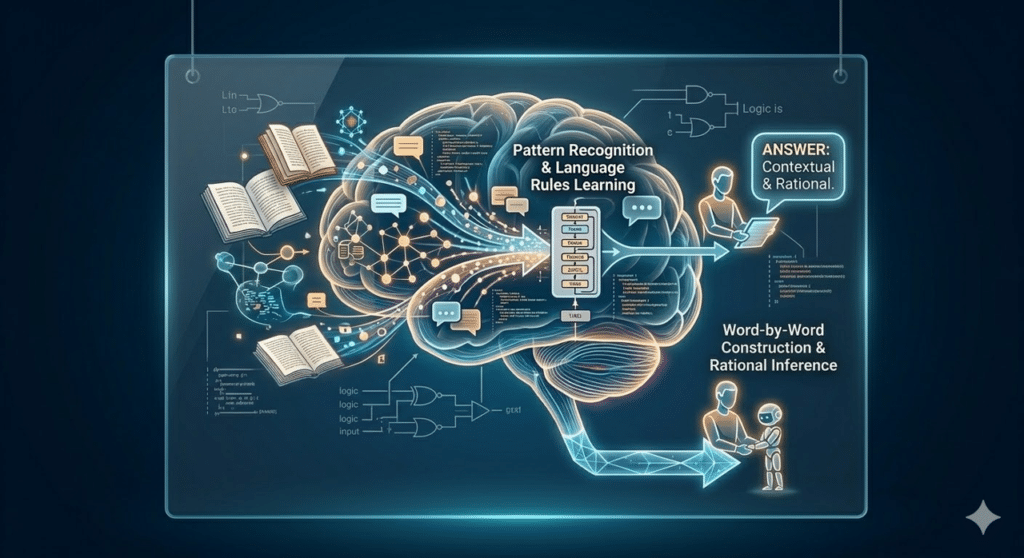
Immaginate un aiutante virtuale instancabile che ha “studiato” miliardi di testi, libri e articoli su internet. Ha immagazzinato una conoscenza sterminata sulle regole della logica e del linguaggio umano, ma la sua mente è “congelata” al momento in cui ha terminato questo addestramento. Quando gli fate una domanda, non “cerca” la risposta in un archivio come farebbe Google: la costruisce parola per parola, scegliendo ogni volta la continuazione più probabile e sensata basandosi su tutto ciò che ha imparato a conoscere.
Questo è, in sostanza, un Large Language Model: un sistema addestrato su moli di dati impressionanti per imparare i pattern del linguaggio e replicare il ragionamento umano.
La vera magia — e la vera sfida — arriva quando volete che questo aiutante conosca anche i vostri dati aziendali privati: i vostri manuali interni, i ticket di supporto, i contratti. E se vi state chiedendo come far leggere a questi modelli i vostri dati privati senza farli impazzire, vi rimandiamo al nostro precedente articolo: “LLM e RAG – Una parte del Futuro dell’Intelligenza Artificiale Generativa“.
Deep Tech per gli addetti ai lavori
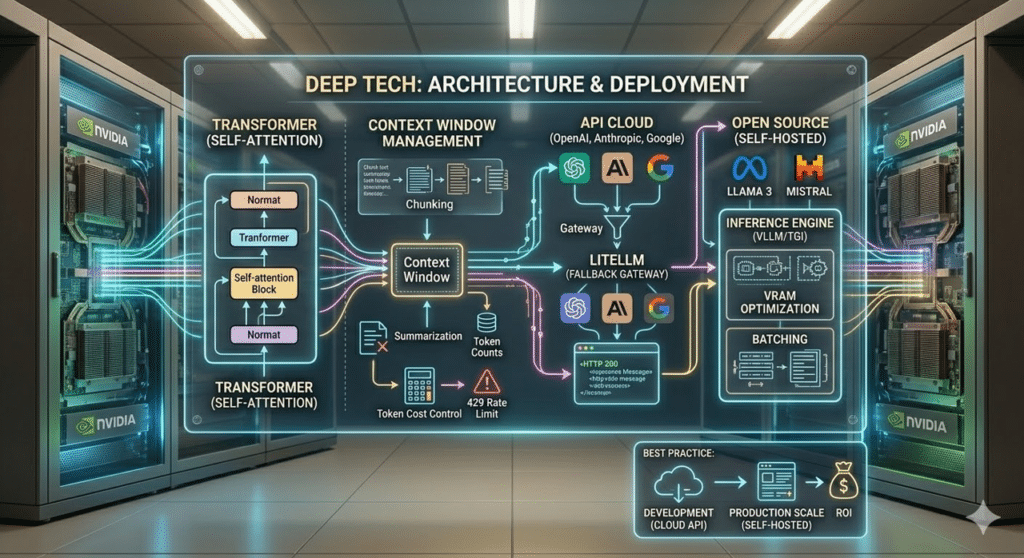
Sotto il cofano, quasi tutti i modelli moderni condividono la stessa architettura: il Transformer. Il cuore pulsante è il meccanismo di self-attention, che permette al modello di pesare dinamicamente le relazioni tra i token di input. Ma cosa significa tutto questo quando apriamo l’IDE?
Innanzitutto, le API degli LLM sono intrinsecamente stateless. Ogni chiamata deve includere l’intero contesto necessario. Questo ci scontra subito con la Context Window: un limite rigido di token elaborabili. Gestire questa finestra richiede strategie architetturali di chunking e summarization per non far esplodere i costi (che si pagano per token in ingresso e in uscita) o incappare in fastidiosi errori HTTP 429 di Rate Limit.
Un altro scoglio critico è la latenza. Aspettare 5-10 secondi per una risposta HTTP standard distrugge la User Experience. La soluzione? Implementare Server-Sent Events (SSE) nel backend per fare lo streaming dei token verso il frontend in tempo reale.
Quando si progetta l’infrastruttura, le opzioni sono due:
- API Cloud (OpenAI, Anthropic, Google): Setup immediato e nessuna risorsa hardware da gestire. Tuttavia, vi espone a vendor lock-in e latenze imprevedibili. La best practice qui è usare gateway (come LiteLLM) per implementare logiche di fallback automatico se un provider va offline.
- Open Source Self-hosted (Llama 3, Mistral, Qwen): Garantisce latenza prevedibile e privacy assoluta sui dati aziendali. La sfida? Serve hardware (GPU come le NVIDIA A100 o H100) e bisogna gestire engine di inferenza avanzati (come vLLM o TGI) per ottimizzare la vRAM e il batching delle richieste simultanee.
Il nostro consiglio architetturale: partite sempre con i modelli Cloud per validare il caso d’uso e il ROI. Valutate la migrazione su un cluster self-hosted solo quando i volumi in produzione rendono i costi delle API insostenibili o se la compliance lo esige fin dal day one.
Conclusione e prossima puntata
Oggi avete nel cassetto una visione chiara: cosa sono gli LLM, perché conviene investirci ora e le vere sfide tecniche per integrarli a livello architetturale.
Ma conoscere lo strumento è solo il primo passo. Come lo si usa per ottenere risultati infallibili?
Nella prossima puntata vi portiamo nel cuore della questione: “Prompt Engineering: l’arte di parlare con l’AI”. Scoprirete come trasformare richieste vaghe e risultati casuali in output precisi, ripetibili e pronti per la produzione.
Stay tuned. La prossima puntata uscirà tra un mese.