
Written by Mattia Gottardello – Full-stack Developer in AzzurroDigitale
Large Language Models and RAG systems are transforming the way companies use artificial intelligence. These technologies enable the automation of customer support with accurate responses, the intelligent management of business documents, and the querying of databases in natural language. This article explores how these tools work, the concrete benefits for businesses, and the technical limitations to keep in mind: a strategic guide to integrating generative AI into your company.
Why LLM and RAG are a game changer for businesses
LLM (Large Language Model) and RAG technologies (Retrieval-Augmented Generation) are revolutionising the way companies can manage, enhance and make available their knowledge. In a context where the amount of data and documents grows every day, finding the right information quickly becomes an increasingly complex challenge. This is where LLMs and, above all, RAG systems come into play.
Imagine a company that needs to provide technical support to customers: thanks to a RAG system, the chatbot can consult manuals, FAQs and internal documentation in real time and respond accurately even to very specific questions, drastically reducing waiting times and improving customer satisfaction. Or think of a team of consultants who, instead of searching through dozens of files and regulations, can obtain accurate and up-to-date answers simply by asking a question in natural language.
These technologies also enable:
- Automate repetitive processes such as compiling reports, searching for data or generating documents
- Reduce the risk of errors with answers based on verified and up-to-date sources
- Customise the user experience by drawing on both public data and confidential company information
- Integrate structured and unstructured data: RAGs can combine information from databases and documents, offering a comprehensive and cross-cutting view
and all this without having to retrain the model every time the data changes.
Of course, adopting these solutions requires careful consideration: technical limitations (such as token, chunk and vector management), infrastructure costs and the quality of the sources used must all be evaluated. However, the benefits in terms of efficiency, speed of access to information and quality of service are such that LLM and RAG are a strategic choice for all companies that want to innovate and remain competitive.
In this article, you will discover how these technologies work, what their limitations are, their most common use cases, and the challenges you will face in successfully adopting them in your business.
What is an LLM?
A Large Language Model is an artificial intelligence trained on enormous amounts of text to understand and generate natural language. These models, such as GPT-4, are capable of answering questions, writing texts, translating languages, and much more.
Examples of everyday use:
- Smart chatbots (e.g. virtual assistants)
- Automatic generation of emails or documents
- Automatic translation
Training and operating these models requires enormous computational resources, such as powerful GPUs (Graphics Processing Units) and specialised servers. Even everyday use (inference1) can require a lot of computing power, which is why they are often run on the cloud.
Limitations of LLMs: updating and cultural bias
One of the main limitations of LLMs is that their knowledge is limited to the date on which they were trained. This means that everything the model “knows” comes from the data collected up to that point: events, scientific discoveries, social or technological changes that occurred after the end of training are not present in its “memory”. For example, an LLM trained in 2023 will not know about events that occurred in 2024 or 2025.
Furthermore, LLMs reflect the culture, values, and biases present in the data on which they were trained. If the source texts are predominantly in one language, from a certain geographical area, or represent a certain way of thinking, the model will tend to reproduce those same perspectives. This can lead to responses that are not neutral or that do not take cultural and social diversity into account.
For these reasons, it is important to use LLMs critically, be aware of their limitations and, when necessary, integrate them with technologies such as RAGs that allow access to up-to-date and more specific information.
RAGs, Explained
Retrieval-Augmented Generation is a technique that combines the power of LLMs with the ability to retrieve up-to-date information from external sources (databases, documents, the web). In practice, the model does not rely solely on what it has learned during training, but can “go out and find” fresh and relevant information.
In this way:
- Answers can always be up-to-date and grounded in real data
- The risk of fabricated responses is reduced because the model is based on concrete sources
- You can customise responses using company or private data
- LLMs are becoming increasingly useful, evolving into flexible tools better suited for professional and fast-changing environments.
How does it work in practice?
Here’s what happens when you ask a RAG system a question:
- Search its archives or the internet for the documents most relevant to your request
- Pass this information to the language model
- Generates a more accurate and up-to-date response.
Examples of RAG usage:
- Advanced search engines (e.g. Perplexity, Bing Chat): they respond by citing up-to-date sources
- Customer support: chatbots that respond to questions about products and services using internal documentation
- Business tools: intelligent search for documents, policies, manuals.
The quality of the responses depends directly on the quality and relevance of the sources to which the model has access: the more reliable and consistent with the request the retrieved documents are, the more accurate the output will be. For this reason, it is essential to integrate the system with the right sources, which can be company databases, internal knowledge bases or content from the web.
When we talk about systems that “read” and “understand” large amounts of text, we must remember that machines do not interpret words in the same way we do. In order to process language, computers must transform text into a form that they can understand and manipulate. This is where concepts such as tokens, chunks, vectors and similarity searches come into play: tools that allow RAGs to efficiently divide, represent and compare text in order to identify the most relevant information and generate pertinent responses.
Why we talk about tokens, chunks, vectors and similarity search
RAGs are systems that combine the ability to generate text (as large language models do) with the ability to retrieve information from a collection of documents or data. This allows for more up-to-date, accurate, and personalised responses.
How does a RAG work in practice?
- Receipt of the question: The user writes a question or request
- Information retrieval: The system searches its archives (databases, documents, web) for the most relevant texts to respond
- Response generation: The language model uses the retrieved information to construct a clear and comprehensive response
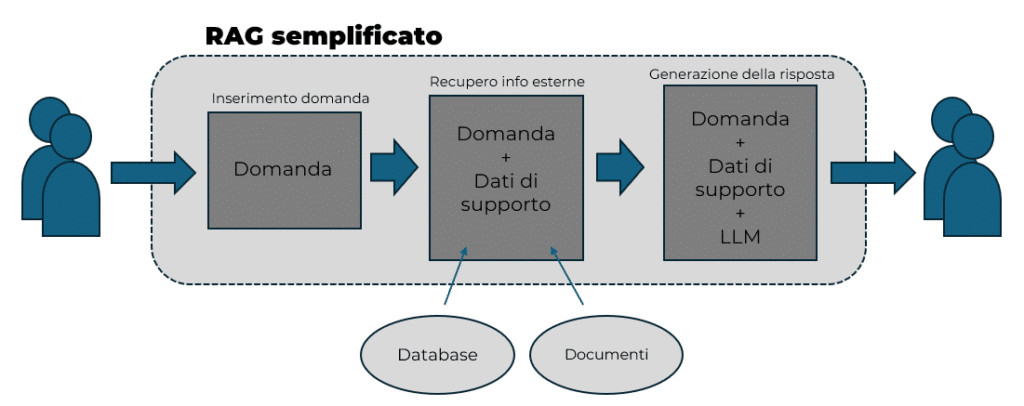
To accomplish this, RAGs must “understand” and compare large amounts of text.
This is where technical terms come into play:
Tokens
LLMs do not read text like a person, but divide it into tokens, i.e. small units (words, parts of words, punctuation). This is done in order to process text more efficiently and uniformly. Each model has a maximum limit on the number of tokens it can handle at one time: if the question or documents are too long, they need to be cut. They are also the fundamental unit on which some AI service providers base their billing systems for paid models.
Chunks
To comply with the token limit, long texts are divided into chunks: small pieces of text, each of which can be processed by the model. This process is essential to allow the system to “digest” even very long documents, but it can result in the loss of some context if important information is spread across multiple chunks.
Vectors
Each chunk of text is transformed into a vector, i.e. a sequence of numbers representing the meaning of that piece of text. This transformation allows the system to compare different texts mathematically, even if they use different words to express similar concepts.
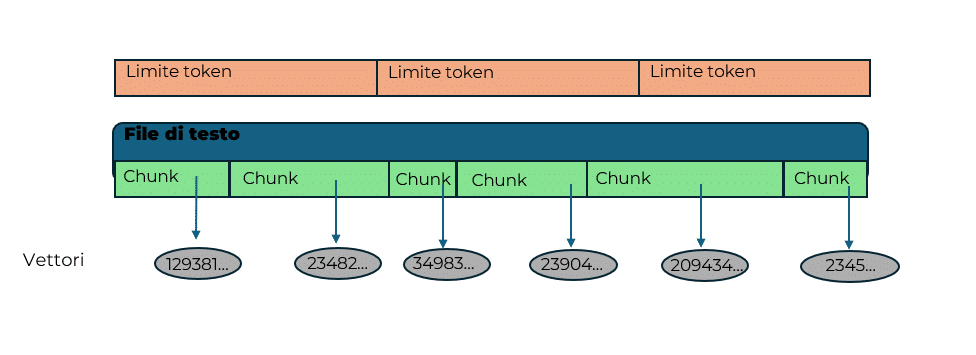
Similarity search
Once all the chunks have been transformed into vectors, the system can use similarity search to find, among all the available pieces of text, those most similar to the user’s query. In practice, the system searches for vectors that most “resemble” the query vector, i.e. that represent similar topics or concepts.
Why is all this important?
- Efficiency: Dividing text into chunks and working with vectors allows large amounts of data to be handled quickly
- Accuracy: Similarity search helps find the most relevant information, even if expressed in different ways
- Technical limitations: Limits on tokens and vector sizes depend on the model used and affect the amount of text that can be analysed and the quality of responses
Operating flows
The purpose of these paragraphs is:
- Support data entry: explain how data is transformed step by step: from the original FILES, which are divided into smaller CHUNKS, to numerical representation using VECTORS, ready to be used by the system
- Question/answer: explain how the system, starting from a question, identifies the relevant support files and generates an answer, providing information that is as accurate as possible and based on the data actually retrieved in relation to the question asked.
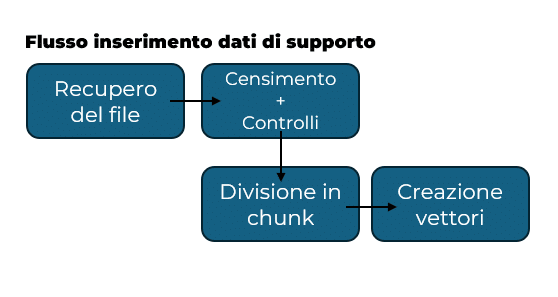
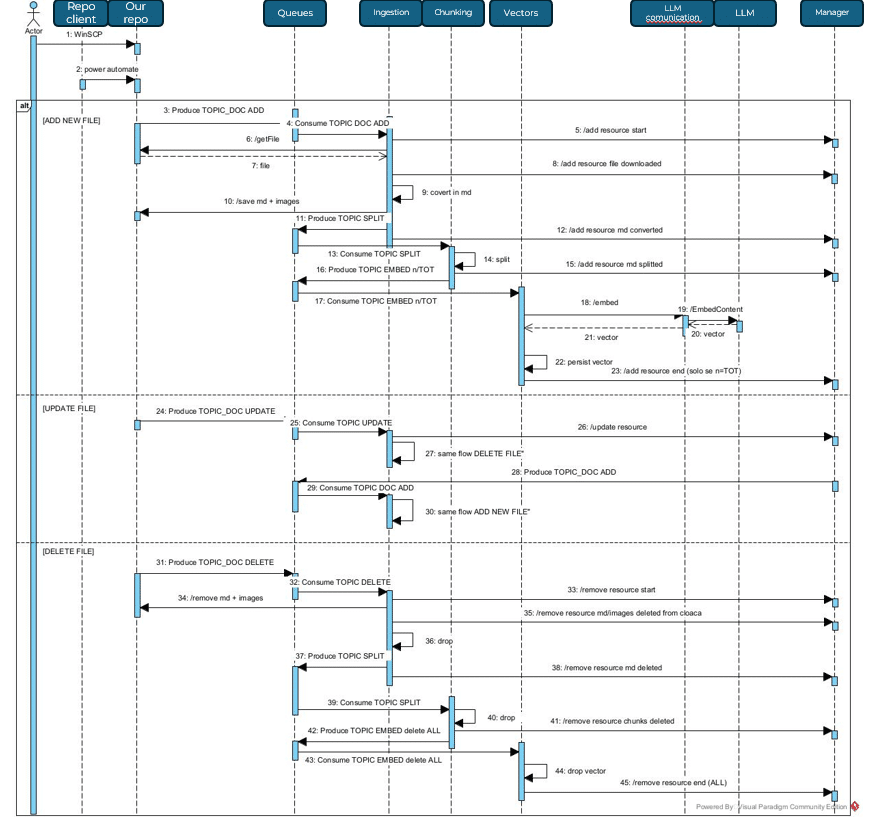
Support data entry flow
We start by retrieving files that the customer can independently place in a remote ‘folder’. Once the system detects the arrival of a new file, part of it takes care of retrieving it. The new document is registered and any checks on file size and format are carried out. This is because it is necessary to know how and with what we are working.
Once we have ensured that the file complies with our constraints, we can start dividing it into chunks according to our chosen methodology. The final step involves conversion to a vector.
At the end of the flow, it will therefore be possible to know, starting from a vector, which chunk it belonged to and, in turn, which file that chunk was generated from.
Question/answer flow:
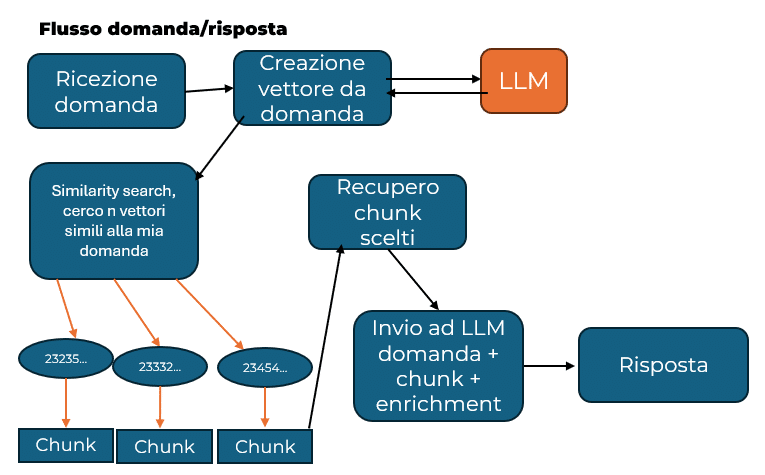
Now comes the moment when the user submits the query: it is converted into a vector and then a similarity search is performed with the vectors present in our system. Obviously, all vectors will give a result because we are measuring a “distance” between two “ideas”, and this distance will always give a value. It is therefore necessary to decide on a minimum threshold that will include the vectors in the candidates for generating the response. The constraint can be imposed both in terms of the minimum value to be included in the set and the maximum number of vectors that can be included.
Once the vectors contributing to the generation of the response have been identified, the process becomes straightforward, as each vector is linked to the chunk that generated it. All the selected chunks will be retrieved and sent together with the question to the LLM, requesting it to generate a response based on the question and the information we have provided.
It is possible (though not advisable) to feed additional files into the response generation system that set or attempt to set guidelines for the LLM’s response.
We have named these files enrichment files.
Wepladoo for Fratelli Poli
In the business case addressed by our team (if you want to learn more, you can find it here), the customer asked us to develop a chatbot capable of answering specific questions using two main sources of information: company documents made available by the customer through a remote folder and data stored directly in the Wepladoo application database. The goal was to enable users to obtain accurate, contextualised answers without having to manually consult either the documents or the database.
What better use for a RAG?
We therefore implemented a web application that performs the operations described above, with which we achieved this objective.
The division of operations allowed us to share responsibilities and processing loads, but made the challenge more complex in terms of orchestrating flows.
We therefore analysed the various LLMs and decided to rely on Gemini for one simple reason: greater flexibility in terms of the size and limits of the text it can handle, both in terms of questions and the amount of information that can be used to obtain answers with supporting data.
We have also set up a mechanism that allows automatic file recovery, so that the system is always up to date based on what the customer uploads to our remote ‘folder’.
The prompt engineer played an important role. Since we had to provide limits and guidelines for generating responses, we developed prompts (in short: phrases, small pieces of text) that are always attached to questions, and the quality of these files is directly proportional to the generation of good responses.
An additional challenge was linked to the fact that the customer requested to be able to obtain information about the Wepladoo application directly from the chatbot. So we came up with a mechanism that works in a very similar way to a normal RAG but also retrieves data (directly from the database) updated at the time of the query to provide a response to the user.
The system, integrated with Wepladoo, has enabled operators to access information in real time from various company documents and from data in the database, greatly simplifying the search for and retrieval of answers.
Deep Tech for Insiders
How does a RAG work?
A typical RAG system consists of two main parts:
- Retriever: Given an input (e.g., a query), it searches for the most relevant documents in a database or vector index (often using embedding techniques such as FAISS, Pinecone, or Elasticsearch)
- Generator: The LLM takes the retrieved documents and uses them as context to generate an accurate and informed response.
Division of tasks
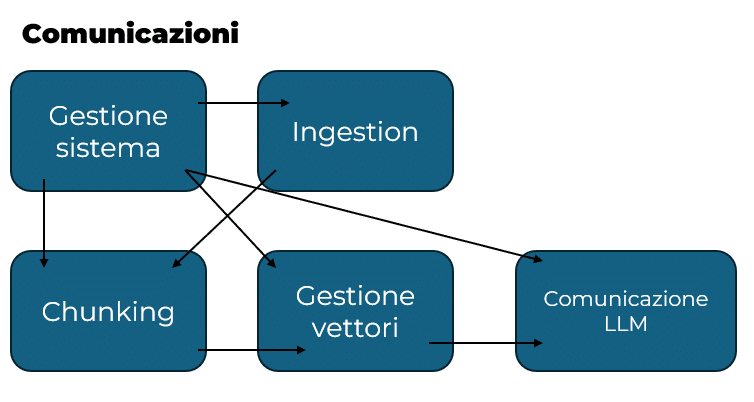
The development of a RAG can be carried out using a monolithic infrastructure or micro-services, depending on requirements. The components involved, viewed as methods or individual micro-services, concern:
- File ingestion: retrieve and manage updated data sources that will then be used as a basis for generating responses
- File chunking: dividing recovered files so that they fall within the limits described above for the various LLMs
- Conversion to vector format: conversion of generated file fragments to vector format and cataloguing of these fragments according to the file to which they belong
- Manage the question-answer flow: once the vectors, chunks and files have been prepared, it is necessary to put into practice the actual functioning of the RAG, i.e. the implementation of the retrieval system and the use of the generation system.
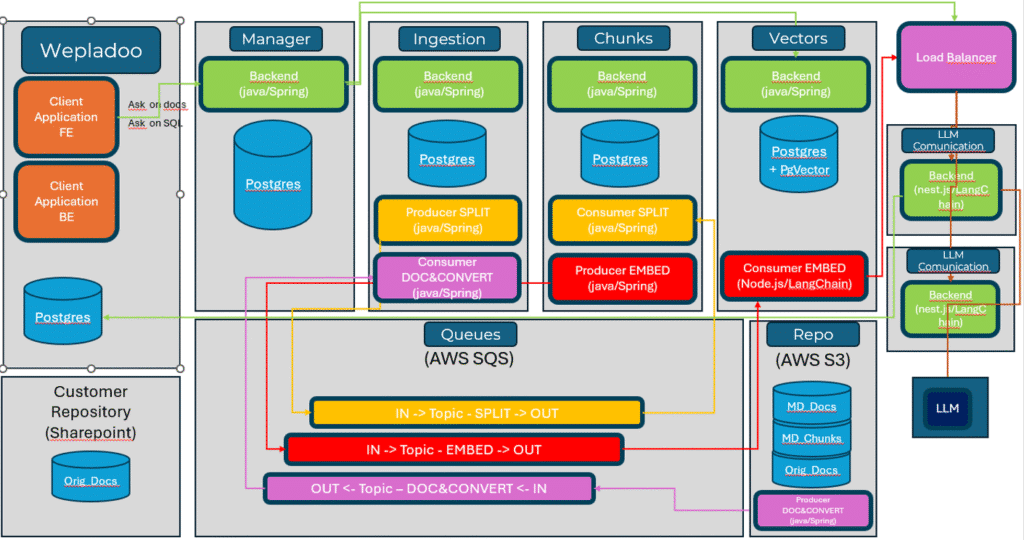
Ingestion
This process must provide for the remote or fixed-location retrieval of one or more files, their initial cataloguing within the system, and the management of the various supported formats.
The decision on which formats to support will affect the chunking process, which is the first point at which the file content is actually accessed. The system must be able to recognise which formats are allowed and which are not, in order to prevent unsupported files from entering the system and rendering the entire application unusable.
File census is also very useful for providing features related to updating files uploaded at different times, removing obsolete files that no longer contribute or cannot contribute to generating responses, and/or simply checking what data the generated responses are based on (citing sources).
The entire ingestion process also uses a queue system, which allows the various updates to be received in an orderly manner in the remote folder, preventing system congestion in the event of massive inputs and improving the entire flow from census to vectorisation.
Next, we will look at the call flow to ensure correct implementation of the system.
Chunking
File chunking is the second step towards the complete processing of new information. Knowing the limitations of the linguistic model on which it is based and being aware of the differences between one chunking method and another, it is necessary to choose how to proceed in order to divide the files that have been brought into the system.
In short, it is necessary to understand after how much text to create a chunk.
There are several chunking methods, each with its own pros and cons:
- Token-based chunking: the text is divided into chunks containing a fixed number of tokens (e.g. 256 or 512 tokens per chunk)
- Chunking based on paragraphs or sentences: the text is divided according to the natural boundaries of sentences or paragraphs
- Chunking with overlapping: each new chunk shares part of the text with the previous chunk (e.g., 50 overlapping tokens)
- Semantic chunking: the text is divided according to meaning, automatically identifying points where the topic changes or a concept ends
- Customised chunking: chunking is adapted to the specific requirements of the application (e.g. sections of manuals, chapters of books, database entries).
Conversion to vector
Once the chunks that comply with the constraints imposed by the LLM in use have been generated, you can move on to generating the vectors.
The vectors will then be saved and linked both to the chunk from which they were generated and to the file to which that chunk belongs. This will allow you to obtain the sources from which a given response originated.
The conversion to vector format is mainly used to perform similarity searches, which allow the extraction of the chunks most similar to the user’s query, thereby significantly increasing the likelihood of obtaining a relevant response to the query submitted to the system.
To perform a similarity search, the query must also be converted into a vector, which means that there will also be a character limit for queries.
Similarity search techniques
Similarity search is the process that allows RAG systems to find, among many pieces of text (chunks), those most similar to the user’s query. There are several techniques for comparing vectors representing texts, each with advantages and limitations:
- Cosine Similarity
- Euclidean distance
- Manhattan distance (or L1)
- Approximate Nearest Neighbor (ANN)
There are also more sophisticated methods, such as similarity based on neural networks or the use of hashing to reduce the complexity of calculations. These techniques are chosen based on the requirements for accuracy, speed and available resources.
Communications to LLM
To interact with LLM models, you can use libraries that, through dedicated methods, provide the APIs of different AI providers in a single location.
A notable example is LangChain, which offers support for both JavaScript and Python. Since most of these technologies originate in the Python environment, implementation in this language is more comprehensive and mature than in JavaScript, which nevertheless guarantees all essential functionality.
Thanks to these tools, functions have been developed that make it easy to generate vectors and send queries to various LLMs, using only access keys and specifying the desired model.
Question/Answer
Here is a small representation of the call flow regarding the generation of the response starting from the question.
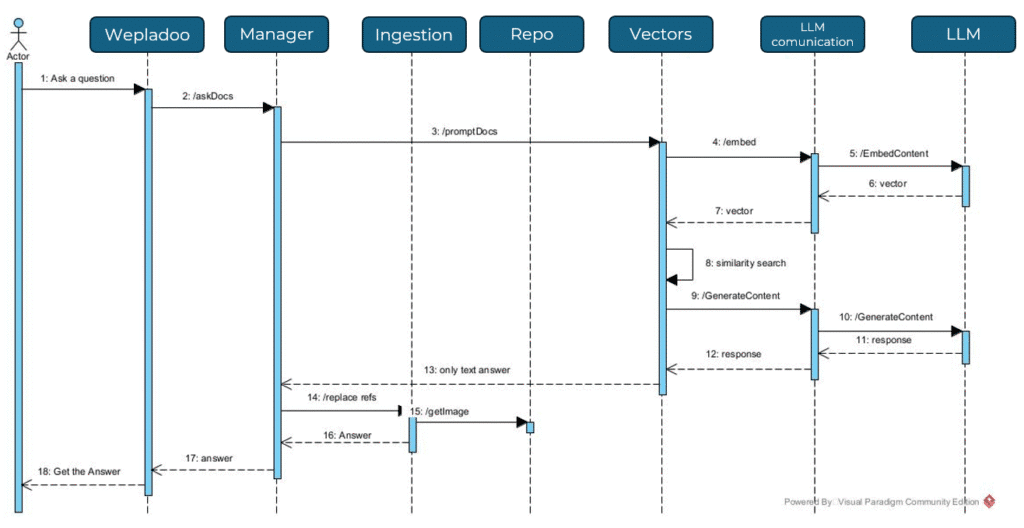
RAG DB connected
The implementation of this small variation on a standard RAG adds an additional step, which is to retrieve information directly from a remote database.
A fundamental requirement is knowledge of the database structure, which will enable you to request the generation of a query
2
to retrieve the data to be used to generate the response.
The preparation flow is therefore as follows:
- create a file containing (in SQL language
3
)
the instructions used to create the database of interest - have the system process the file as if it were a normal document file
- use the file without exploiting similarity search (we know that the structure is static and therefore contained only in that file, which in turn generates or can generate a chunk)
The question-answer flow:
- Obtain the application form
- Recover the file containing the database structure
- Ask the chosen LLM to generate a query that leverages the combination of the question and the database structure
- Various checks to validate/block dangerous operations and execute database queries
- Achieving results (which may or may not be present)
- Generation of the response, which once again involves the question together with the results obtained; this time, the response will be provided in natural language
To facilitate the management of the two mechanisms, it was decided to keep the two chatbots separate, even graphically: one allows users to ask questions and obtain answers based on documents, while the other is based on database data.
Developer Glossary
- Inference is the stage at which an artificial intelligence model is used to generate responses or make predictions after being trained. In practice, when you write a question or text, the model processes the input and produces an output (e.g., a response or sentence completion). Unlike training, which requires a lot of computing power and time, inference is when the model “puts into practice” what it has learned, typically in real time or near real time, to provide answers to users.
↩︎ - A query is a request made to a database or computer system to obtain specific information, usually using a structured language such as SQL.
↩︎ - Structured Query Language, a language that allows queries and operations to be performed on a database.
↩︎