
Article by Nicola Boscaro – Full-stack Developer at AzzurroDigitale
The first episode of “LLM in the Real World” is designed for entrepreneurs, managers, and tech teams who want to understand whether LLMs are truly a concrete opportunity for their company. The goal is to move beyond the hype and explain, clearly and practically, how to use them to generate real value. Through use cases, architectural choices, and a comparison between Cloud and Open Source, the article shares experiences and lessons learned directly from the development team, with a focus on results, costs, and production deployment.
Welcome to the first episode of “LLM in the Real World,” the miniseries where our development team stops talking theory and shows you what it really means to bring generative AI into production. No hype, no magic—just concrete use cases, real architectures, and lessons learned firsthand. Buckle up.
Business Case: Understanding the Value for the Company
Let’s start with a straightforward question: why should your company invest in LLMs today, rather than two years from now?
The answer is simple: your competitors are probably already doing it.
LLMs are not just “sophisticated chatbots.” They are engines capable of understanding, analyzing, and generating text at unprecedented speed. This means you can take slow, cumbersome business processes that currently eat up hours of manual work and complete them in a matter of seconds. Think of:
- Customer support that responds consistently and personally, 24/7, without a call center.
- Document analysis (contracts, emails, reports) that are automatically classified and summarized.
- Conversational interfaces that allow your employees to query complex business data in natural language, without needing to know SQL.
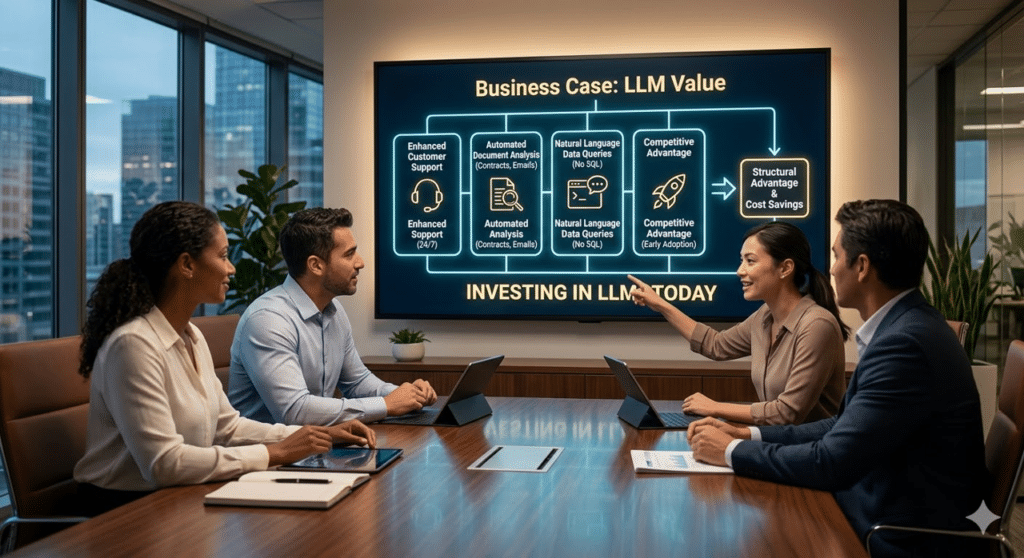
The competitive advantage doesn’t lie in adopting AI—it lies in doing so before it becomes the standard. Those who build their intelligent pipelines today will gain a structural edge that will be hard to catch up with.
How It Works: Simplifying Complexity
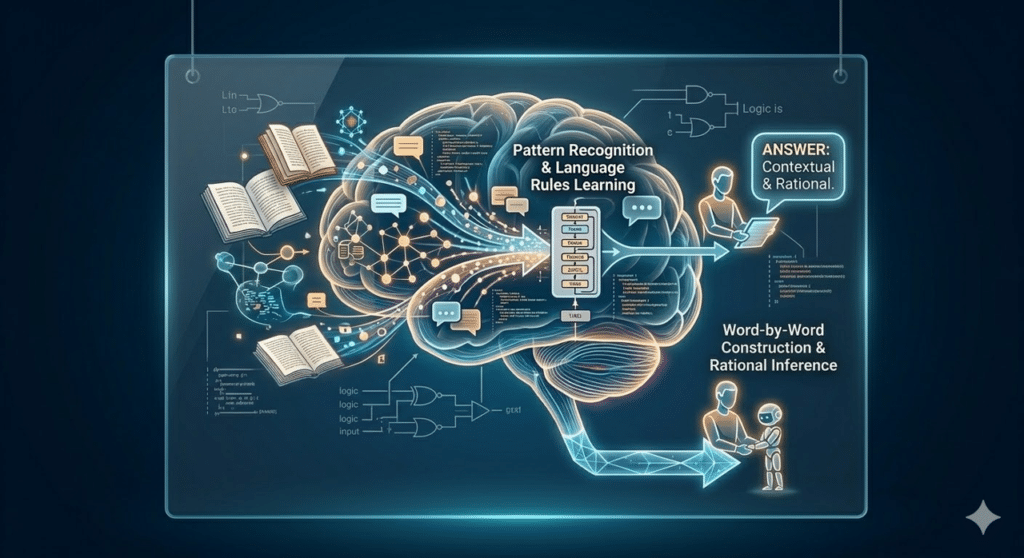
Imagine a tireless virtual assistant that has “studied” billions of texts, books, and articles across the internet. It has stored vast knowledge about the rules of logic and human language, but its “mind” is frozen at the moment its training ended. When you ask it a question, it doesn’t “search” for an answer in a database like Google would; it constructs the response word by word, choosing each next word based on the most likely and sensible continuation according to everything it has learned.
This is, essentially, a Large Language Model: a system trained on massive amounts of data to learn language patterns and replicate human-like reasoning.
The real magic—and the real challenge—comes when you want this assistant to also know your private business data: your internal manuals, support tickets, contracts. And if you’re wondering how to let these models read your private data without overwhelming them, we refer you to our previous article: “LLM and RAG – A Part of the Future of Generative Artificial Intelligence.”
Deep Tech for Insiders
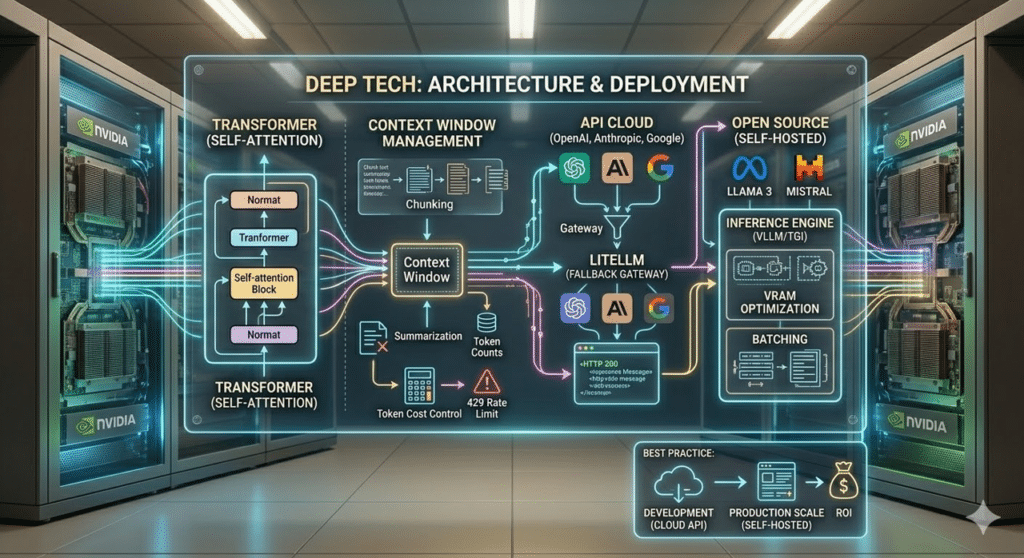
Under the hood, almost all modern models share the same architecture: the Transformer. At its core is the self-attention mechanism, which allows the model to dynamically assess the relationships between input tokens. But what does all of this actually mean when you open the IDE?
First of all, LLM APIs are inherently stateless. Each call must include the entire necessary context. This immediately runs into the Context Window: a hard limit on the number of tokens that can be processed. Managing this window requires architectural strategies like chunking and summarization to avoid skyrocketing costs (which are charged per input and output token) or running into annoying HTTP 429 Rate Limit errors.
Another critical hurdle is latency. Waiting 5–10 seconds for a standard HTTP response can ruin the user experience. The solution? Implement Server-Sent Events (SSE) on the backend to stream tokens to the frontend in real time.
When designing the infrastructure, there are two options:
- Cloud APIs (OpenAI, Anthropic, Google): Immediate setup with no hardware to manage. However, this exposes you to vendor lock-in and unpredictable latency. The best practice here is to use gateways (like LiteLLM) to implement automatic fallback logic if a provider goes offline.
- Open Source Self-Hosted (Llama 3, Mistral, Qwen): Provides predictable latency and complete privacy for company data. The challenge? You need hardware (GPUs like NVIDIA A100 or H100) and must manage advanced inference engines (like vLLM or TGI) to optimize VRAM usage and batch simultaneous requests.
Our architectural recommendation: always start with Cloud models to validate the use case and ROI. Consider migrating to a self-hosted cluster only when production volumes make API costs unsustainable or if compliance requires it from day one.
Conclusion and Next Episode
Today, you have a clear vision: what LLMs are, why it’s worth investing in them now, and the real technical challenges of integrating them at an architectural level.
But knowing the tool is just the first step. How do you use it to achieve reliable results?
Nella prossima puntata vi portiamo nel cuore della questione: “Prompt Engineering: l’arte di parlare con l’AI“. Scoprirete come trasformare richieste vaghe e risultati casuali in output precisi, ripetibili e pronti per la produzione.
Stay tuned. The next episode will be released in a mont h.